All code related for this project can be found at "public" GITHUB repository here:https://github.com/andreylisovskiy/linear_regress.git
Coming from mostly Python lifestyle, where I have spent most of my last few years, into this more extensive use of JS, where I now
use it not only to dynamically change web elements on my web app but also for data processing, I could tell you that it was a little
rough on me.. I feel like it was a lot easier to import modules and access system feature in Python as opposed to doing the same in-browser
with JS... Because Python works at system/server level, it has more access, privileges, rights, than importing modules and loading files from
client/browser side with JS has.
It was a change for me as for my prior written web apps I have outsourced most of the data processing and heavy lifting to python
via Ajax calls to server script.
And left JS in browser use to minimum, mostly used for UI and page dynamics.
The task was super self-explanatory and simple in my head though. I had all the dots connected. So, I thought it was supposed to be a breeze.
But what took me a lot of time was trying to hack a browser to allow me to load a local file for testing and presentation purposes through browser.
Too much time was just wasted trying to make browser and XLSX happy about reading a local project file with relative path in project.
It kept getting stalled without producing any errors. And on some other more promising tries when using:
let workbook = XLSX.read(file_path);
it was giving me this error message where it looks like "t" object was being miss-used inside "XLSX.full.min.js" because it failed to
read the file in:

The above error was also seen while trying to emulate/utilize the XLSX doc snippets on loading remote files via async fetch and XMLHttpRequest
methods.
Anyways, enough of whining, it was probably due to my lack of experience trying to read local/remote files into the browser without human
interaction, but I just wanted to document and talk about my path to end goal solution and depict the most memorable times.
I understand that this functionality gets blocked by browser for security purposes. I have used XLSX before via a "dropdown" or
"file explorer" input options successfully thus have not had these file loading issues before.
Thus, in "Test Drive" section below, I have implemented the file explorer option which you can use to upload that excel/csv file with
Boston House pricing dataset in CSV or XLSX format. Here is the link if you wish to download a copy of that CSV:.
https://linear-regress.pages.dev/data/BostonHousing.csv
It took me few minutes to find file for Boston House pricing that was not missing data and had the same record order as
"http://lib.stat.cmu.edu/datasets/boston" page.
The goal of this snippet is to replace Tensorflow ML lib components:

with much nicer XLSX lib + Simple-Statistics methodology, which allows to load real world data input formats and utilizes more light weight and much
simpler approach for a simple problem. Depiction of system:

There is a great difference between the two methodologies. Tensorflow is ML training on given feature and label using linear
regression model, while Simple Statistics is just using simple math methodology using single equation formula of "least sum
of squares". Also, ML frameworks usually require more data "treatment" due to training algorithms being more prone to skewness from un-clean
data. And the model schema design options are super broad and almost infinite. Simple
Statistics on other hand may only require some missing value and outlier treatment for good results, and there is no requirement for
shuffling, normalization, or layer definition on user part, it just follows the same "model" (so to speak) every time which is a set-defined
mathematical equation formula.
These are the main/core functions inside index.html javascript file that I have built for this snippet's purpose:
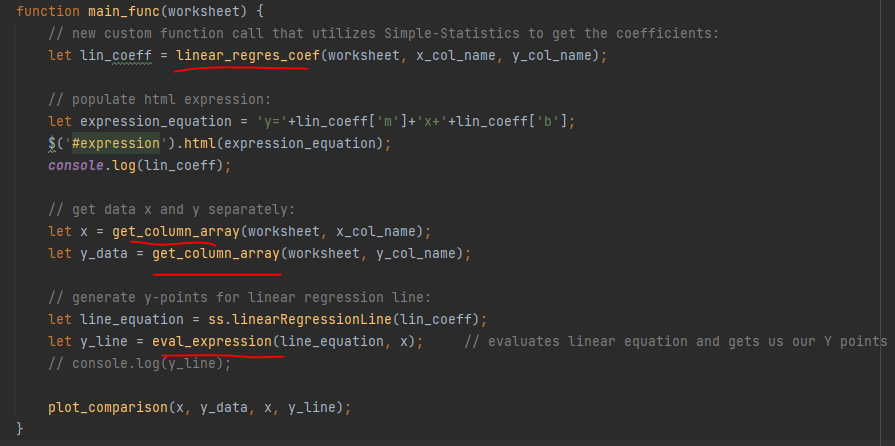
And they are defined in ./JS/my_js.js
In conclusion. I that could complete the task of connecting these components: CSV/XLSX files, XLSX, and Simple-Statistics to
get the output results that we want in form of best fit linear equation coefficients, the formula, and evaluation object.
Although, there is more that could be done around this topic: like building comparable Tensorflow model and comparing on same data
between this method and Tensorflow's model results. I believe this function/method could also use other "helper" methods to be built
to support some basic "data cleaning" that could be needed for better results.. Like: missing "missing_value_imputation" and
"outlier_drop" methods.
As usual, now its time to test drive this new functionality in playground bellow.